
Что такое имитация отжига?
Имитация отжига (отжиг) - основной алгоритм в контестах на оптимизацию. Почти каждый победитель Topcoder Marathon или Atcoder Heuristic Contest скорее всего когда-то писал отжиг. В интернете есть много статей про этот алгоритм, поэтому я предполагаю, что вы уже знакомы с основами. Я рекомендую вот эту. (прим.: она на английском, подойдёт и статья с Алгоритмики).
Проблема всех этих статей в том, что в них объясняется, как работает алгоритм, но нет идей о том, как подбирать параметры. Мы попробуем это исправить.
Дисклеймер: У меня самого не так много опыта в оптимизационных контестах, поэтому ко всему сказанному здесь стоит относиться с осторожностью. Но, тем не менее, я был членом команды, которая дважды побеждала в Google HashCode, в котором отжиг может использоваться в решениях.
Задача коммивояжёра (Traveling Salesman Problem, TSP)
В этой статье мы проанализируем использование отжига для решения одного конкретного случая задачи коммивояжёра. Даны n городов и расстояния между каждой их парой. Нужно найти кратчайший цикл, в котором каждый город посещается ровно один раз. Я взял задачу из старого блога на CF, там 100 городов.
Как использовать отжиг для решения задачи коммивояжёра? Для начала заметим, что решение может быть представлено как перестановка от 1 до n – это порядок, в котором мы посещяем города. Далее нужно понять, какие здесь возможны переходы. В нашем случае мы будем использовать один из возможных переходов, который называется 2-opt – берём случайный подотрезок перестановки и переворачиваем его.
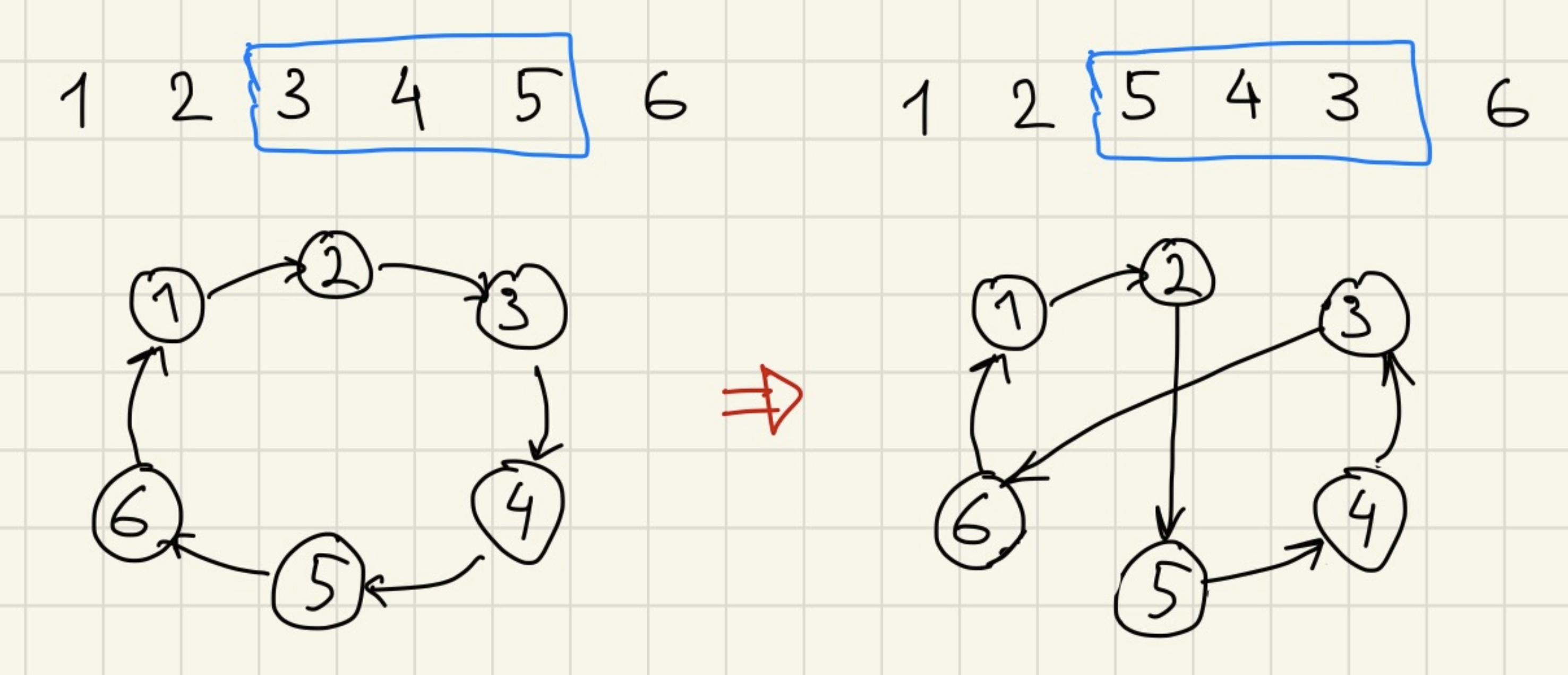
Код
Давайте напишем какой-нибудь код. Проблема в том, что во всех статьях про отжиг можно найти разные формулы, разные способы изменения температуры, различные <X>… Что именно мы должны использовать?
Кстати, думаю, это именно то, что останавливало меня от использования отжига в прошлом. Среди множества туториалов я выбирал один случайный, он не работал хорошо и я просто использовал другие алгоритмы, которые знал.
Но теперь я знаю правильный способ. Мы можем просто подсмотреть код у Psyho :) Я открыл его решение с последнего контеста Atcoder Heuristic, и знаете, что я увидел? Правильно, реализацию отжига.
Поэтому я написал код для коммивояжёра, который использует те же формулы (но с другими temp_start and temp_end):
const MAX_SEC: f64 = 1.0;
let temp_start = 10.0f64;
let temp_end = 0.001f64;
let start = Instant::now();
let mut perm: Vec<_> = (0..n).collect();
let mut prev_score = calc_score(&dists, &perm);
loop {
let elapsed_s = start.elapsed().as_secs_f64();
if elapsed_s > MAX_SEC {
break;
}
let elapsed_frac = elapsed_s / MAX_SEC;
let temp = temp_start * (temp_end / temp_start).powf(elapsed_frac);
let (fr, to) = pick_random_interval_to_reverse(n);
perm[fr..to].reverse();
let new_score = calc_score(&dists, &perm);
if new_score < prev_score || fastrand::f64() < ((prev_score - new_score) / temp).exp() {
// Переходим в новое состояние!
prev_score = new_score;
} else {
// Откат
perm[fr..to].reverse();
}
}
let score = calc_score(&dists, &perm);
eprintln!("Score: {score}");
Он допольно короткий! И, скорее всего, работает лучше, чем большинство умных алгоритмов, которые вы можете предложить!
Здесь происходит немного магии в частях с temp_start * (temp_end / temp_start).powf(elapsed_frac) и
fastrand::f64() < ((prev_score - new_score) / temp).exp(). Понимание того, как они работают, оставлю как упражнение читателю,
но на самом деле вам и не особо нужно это знать. Можно просто копировать их каждый раз, когда пишете отжиг.
По-настоящему интересная часть – вот эти две строчки:
let temp_start = 10.0f64;
let temp_end = 0.001f64;
Как мы должны подбирать эти константы? Здесь я выбрал их примерно случайно, опираясь на свой опыт, но это не тот совет, который вы хотите получить, не так ли?
Обратно к нашему коду для коммивояжёра. Мы можем его запустить и получить результат:
Score: 7.867000846582566
Это хороший скор? Всё ли хорошо? Можно ли получить результат лучше? Нужно ли поменять наши константы?
На это трудно ответить, имея всего одно число. Сейчас мы никуда не торопимся, поэтому можем просто визуализировать данные, чтобы получить больше понимания насчёт того, что можно улучшить.
Давайте визуализировать!
Дисклеймер: в этой статье много графиков и они интерактивные (можно увеличивать интересующие части). С ними проще взаимодействовать на устройстве с большим экраном. Но если читаете со смартфона, возможно, стоит повернуть экран и перезагрузить страницу.
Для начала нарисуем график скора от времени.
Он выглядит примерно так, как и ожидалось. Мы начинаем с рандомного решения с большим счётом (суммарной дистанцией) и проводим какое-то время с высокой температурой, которая позволяет делать плохие переходы, поэтому в целом скор всё ещё высокий. Но со временем температура понижается и мы медленно сходимся к дистанции меньше.
Иногда также полезно рисовать одни и те же графики, но от нескольких разных запусков, чтобы убедиться в том, что все они выглядят примерно одинаково.
Рассмотрим поближе, что происходит в последние 0.2 секунды.
Немного мыслей:
- Для каждого отдельного прохода, результат на 0.8с примерно такой же, как и на 1.0с, что означает, что мы тратим впустую 20% времени.
- Разные проходы заканчиваются с разными скорами (и разными перестановками), поэтому запуск алгоритма несколько раз может помочь найти более хорошее решение.
Сохранение лучшего результата
Давайте соптимизируем единичный пробег. Мы можем выводить не только текущий результат, но и лучший, который мы пока встретили:
Для каждой точки на оранжевом графике должна быть точка на синем с таким же значением, которое было достигнуто ранее. Но мы не видим этого на графике, потому что для отрисовки графика были взяты не все точки, и многим интересным синим точкам просто не повезло попасть на график.
И приблизим то, что происходило в конце:
Суть того, что я хочу показать здесь, в том, что если мы остановим алгоритм в неподходящий момент и будем использовать последнее решение вместо лучшего (буквально то, что мы делаем в коде выше), то мы можем получить результат намного хуже, поэтому всегда сохраняйте лучший результат вместо последнего.
Выбор параметров
Почему мы проводим последние 20% времени, занимаясь примерно ничем? Почему мы проводим первую половину времени с очень плохим скором?
Попробуем выбрать другие temp_start и temp_end и посмотрим, какой результат мы получим. Для осей используются логарифмические шкалы.
И не забывайте, что графики интерактивные, поэтому их можно всячески крутить! Здесь каждой точке соответствует один эксперимент.
Меньшие скоры лучше, поэтому единственный вывод, который мы точно можем сделать – это то, что temp_end должна быть меньше 0.01 (иначе мы просто делаем плохие переходы до конца и никогда не получаем хорошее решение).
Ок, оставим только параметры поменьше и перезапустим эксперимент.
Хорошо, теперь также скажем, что temp_start должна быть как минимум 0.1 (в ином случае мы не исследуем всё пространство решений и сходимся к локальному оптимуму).
Теперь мы видим, что после удаления очевидно плохих стартовых температур, результаты для всех остальных выглядят довольно случайно. Помимо этого можно сказать, что temp_start = 10.0 и temp_end = 0.001 находятся внутри диапазона.
Лучший ответ
Для конкретно этого случая TSP, существует заранее известный лучший ответ, который мы на самом деле несколько раз уже находили. Давайте посмотрим, с какими стартовыми параметрами это случается чаще. Я нарисовал сетку 10x10 с разными temp_start and temp_end, для каждой из ячеек запустил по 5000 пробегов и посчитал вероятность нахождения оптимального решения.
На предыдущем графике было проблематично сравнивать “разумные” стартовые параметры, но теперь мы можем увидеть некоторые закономерности.
Например, с большой temp_start = 70 всё ещё есть шансы сойтись к оптимальному решению, но вероятность этого может быть в несколько раз меньше в сравнении с лучшими стартовыми параметрами. Вероятно, так происходит потому, что с большой temp_start мы проводим слишком много времени, делая случайные изменения вместо того, чтобы на самом деле пытаться найти хорошее решение.
Теперь я думаю, что начал понимать ответ Psyho насчёт нахождения параметров. Начальная температура должна быть достаточно высокой, чтобы была возможность посетить все возможные состояния, но не выше, потому что так мы будем просто тратить слишком много времени, выбирая случайную стартовую точку.
Построим такой же график Score(Time), какой строили в начале, для более оптимальных начальных параметров (temp_start=0.2; temp_end=5e-3). И снова запустим код несколько раз, чтобы убедиться, что все пробеги выглядят примерно одинаково.
График стал немного другим, правда? Теперь мы не тратим первую половину времени, не делая примерно ничего.
10x1s или 1x10s?
На предыдущей тепловой карте видно, что с хорошими стартовыми параметрами можно достичь оптимального решения примерно в 3% пробегов. Это значит, что в среднем нужно запустить программу 33 раза(и потратить 33 секунды), чтобы получить оптимум. Но возможно, что более оптимально будет запустить алгоритм один раз, но на более длительный период времени. Стоит помнить, что мы выбрали лучшие начальные параметры для алгоритма, работающего одну секунду. Вполне возможно, что при другом времени работы оптимальные параметры будут другими. Но давайте пока об этом не думать.
| Время одного пробега | Вероятность нахождения оптимального решения | Ожидаемое время нахождения оптимального решения |
|---|---|---|
| 0.1s | 0.6% | 16.5s |
| 0.2s | 1.3% | 15.8s |
| 0.5s | 2.3% | 22.1s |
| 1s | 3.0% | 33.0s |
| 2s | 3.5% | 57.5s |
| 5s | 6.4% | 78.1s |
| 10s | 6.5% | 153.8s |
Хорошо, конкретно в этом случае мы можем увидеть, что запуск алгоритма с большим лимитом по времени увеличивает вероятность нахождения оптимального решения, но общая эффективность уменьшается. Поэтому лучше даже сократить TL до 0.2с, и запустить алгоритм несколько раз в течение исходного лимита в одну секунду.
Интуитивно это случается, потому что пространство решений относительно мало, и 0.2с уже достаточно, чтобы подобрать хорошее решение. Но так случается не всегда, для некоторых больших случаев TSP или для друхих задач возможно, что запуск алгоритма единожды на более длительный отрезок времени будет более оптимальным. Поэтому всегда проверяйте, что будет лучше конкретно в вашем случае.
Подбор параметров. Часть 2.
Мы увидели, насколько выбор стартовых параметров может повлиять на вероятность нахождения оптимума.
Например, есть очень плохие решения (слишком маленькая temp_start или большая temp_end), которые приводят к очень плохим результатам. Но в остальных случаях результат скорее всего будет адекватным.
Допустим, если вы зададите temp_start слишком большим и temp_end слишком маленьким значением, то ваш алгоритм потратит первые 40% времени на случайные изменения решения, и последние 40% не делая изменений вообще. Но он всё ещё потратит 20% посередине так же эффективно, как потратил бы с оптимальными параметрами. Поэтому если увеличить TL в 5 раз, получится такой же результат.
Так что если вы решаете отжигом какую-то специфическую задачу локально, вы можете сначала запустить код с очень неэффективными параметрами, оценить, какого результата можно достичь и затем попробовать сдвинуть temp_start и temp_end ближе друг к другу и убедиться, что результат всё ещё достаточно хороший.
Мы можем воспользоваться тем, что функция ожидаемого скора в зависимости от temp_start и temp_end примерно независима по параметрам, поэтому сначала можно найти оптимальную temp_end, и затем отдельно оптимальную temp_start.
Подбор параметров. Часть 3.
Но что мы можем сделать, если мы заранее не знаем тестовый пример? Или если результаты очень шумные и сложно подобрать параметры?
Попробуем посмотреть на на другие статистики. На каждой итерации мы решаем, применять ли какое-то изменение или нет, и в зависимости от этого их можно разбить на три категории:
- Оно улучшает результат, и мы применяем его.
- Оно делает результат хуже, но мы всё ещё его применяем.
- Оно делает результат хуже, и мы его отбрасываем.
Мы можем отслеживать скользящее среднее частей изменений, подходящих под категории (1) и (2).
Вот так выглядит график для наших оптимальных параметров (temp_start=0.2; temp_end=5e-3):
И вот он же, но уже для (temp_start=10; temp_end=1e-3), использованных нами в самом начале:
Они довольно сильно различаются, не так ли? И для различных разновидностей TSP и даже для различных задач, графики оптимальных решений будут выглядеть схоже с оптимальными графиками для этой задачи. Поэтому при выборе параметров для отжига, мы можем построить такой график и попробовать сделать его похожим на первый график тут.
Я также думаю, что должно быть возможно изменять температуру автоматически на основании соотношения категорий 1 и 2, но я никогда не видел, чтобы кто-то так делал. Дайте мне знать, если вы попробовали такой способ!
Оптимизация производительности
Обычно в контестах на оптимизацию лучше тратить время на пробу различных идей, добавление новых видов переходов, и так далее. Перед тем, как делать любые улучшения производительности, попробуйте просто увеличить TL и проверить, даёт ли это сильно лучший результат.
Но если вы на самом деле хотите улучшить производительность, вот несколько предложений.
Для начала всегда выводите количество проверенных переходов в секунду. Попробуйте оценить, насколько большим должно быть это значение, и сравните его с фактическим, если они сильно различаются – попытайтесь понять, почему так произошло.
Например, попробуем прикинуть, каким оно должно быть в нашем случае. Каждый раз мы берём случайный интервал (что занимает O(1)), переворачиваем этот интервал и подсчитываем скор. Переворот и подсчёт результата занимают O(n), где n=100.
Поэтому, вероятно, общее число попыток должно быть больше миллиона и меньше десяти миллионов в секунду.
Я на самом деле написал эту догадку перед тем, как провести замер, поэтому давайте посмотрим, правильно ли я угадал.
Average transitions checked: 10'040'966/s
На самом деле наше решение даже быстрее, чем ожидалось! Но мы всё ещё можем проверять переход за O(1) – когда мы переворачиваем подотрезок перестановки, мы меняем только два ребра на два других ребра.
Это изменение довольно хитрое и требует некоторой осторожности, но примерно выглядит вот так:
let (fr, to) = pick_random_interval_to_reverse(n);
if to - fr + 1 >= n {
// это изменение не делает ничего.
continue;
}
let v1 = if fr == 0 { perm[n - 1] } else { perm[fr - 1] };
let v2 = perm[fr];
let v3 = perm[to - 1];
let v4 = if to == n { perm[0] } else { perm[to] };
// меняем (v1, v2) и (v3, v4) местами с (v1, v3) и (v2, v4)
let score_delta = dists[v1][v3] + dists[v2][v4] - dists[v1][v2] - dists[v3][v4];
let new_score = prev_score + score_delta;
После запуска видим:
Average transitions checked: 20'397'125/s
Хорошо, оно стало быстрее в два раза, но это не выглядит как O(n) vs O(1). Можем запустить код из-под perf и увидеть это:
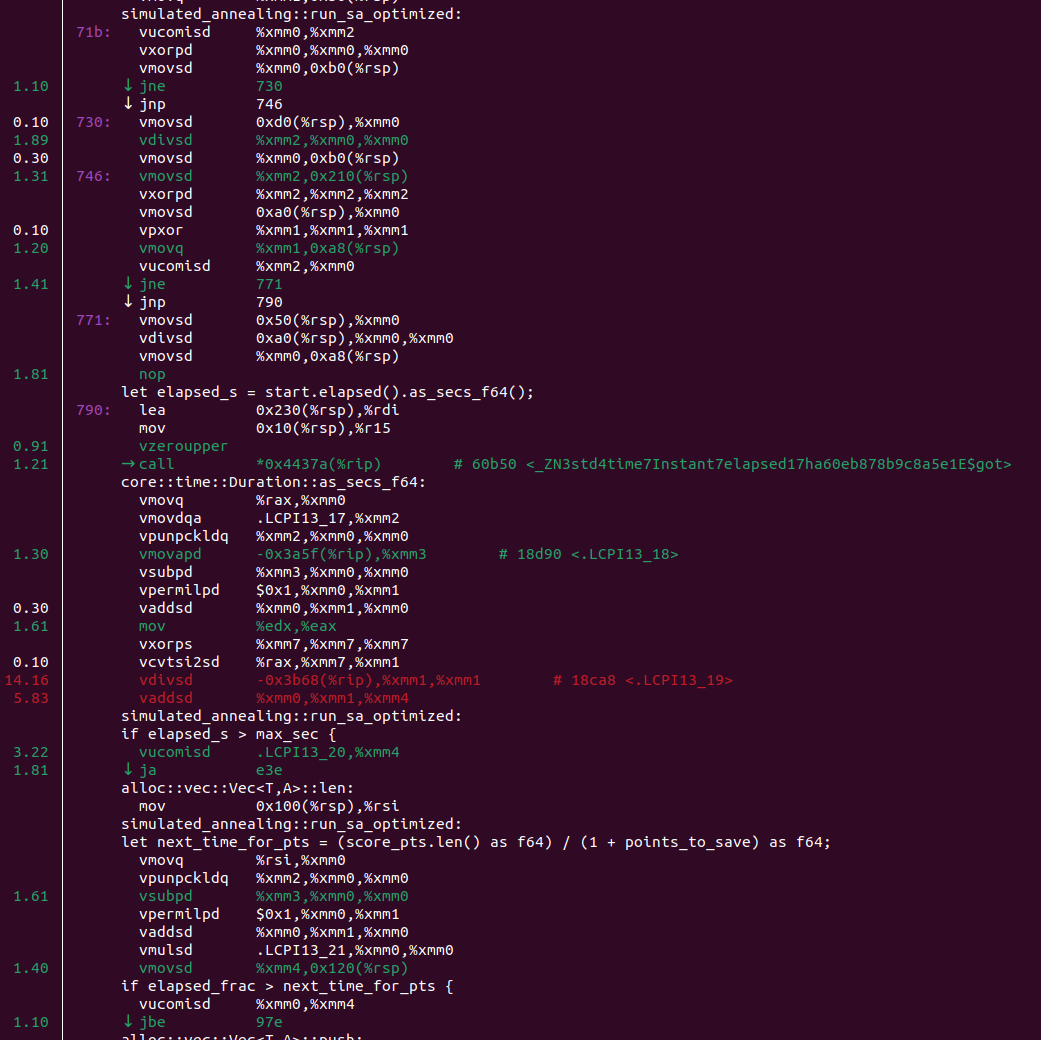
Даже если вы не понимаете asm, вы всё ещё можете заметить подозрительное core::time::Duration::as_secs_f64. И это довольно распространённая проблема в отжиге. Если функция подсчёта скора занимает O(1) и очень быстрая, ботлнеком становится измерение времени – оно нужно, чтобы вычислить оптимальную температуру и определить, когда нужно остановиться.
Оптимизация очень простая. Мы можем обновлять таймер каждые 128 итераций, и просто использовать одно и то же значение для следующих итераций.
Теперь цикл выглядит так:
let mut elapsed_s = 0.0;
for iter in 0.. {
if iter & 127 == 0 {
elapsed_s = start.elapsed().as_secs_f64();
}
...
}
И производительность теперь лучше:
Average transitions checked: 42'284'052/s
Также можем закешировать temp, потому что его вычисление требует тяжёлую функцию powf:
Average transitions checked: 75'977'403/s
fastrand довольно хорош, но мы все ещё можем заменить его на нашу собственную реализацию генератора случайных чисел xorshift:
Average transitions checked: 81'184'596/s
Конкретно в нашем случае мы можем использовать немного некорректную оптимизацию. Давайте создадим const N: usize = 100 (потому что мы знаем размер ввода ещё на этапе компиляции), и будем использовать это N во время генерации случайного отрезка. Чтобы сгенерировать случайное число от 0 до n, мы генерируем случайное 64-битное число и берём его по модулю n. Если n известно на этапе компиляции, компилятор может заменить операцию взятия модуля на более быстрые инструкции.
Average transitions checked: 90'212'640/s
Отлично! Стало в 9 раз быстрее изначальной версии. Я также запускал эту версию много раз с TimeLimit=0.02s и обнаружил, что вероятность нахождения оптимального решения – 1.1% (что примерно одинаково с неоптимизированной версией с TimeLimit=0.2s), и ожидаемое время поиска оптимального решения составляет теперь 1.8s, что значительно лучше в сравнении с исходной версией.
Заключение
Имитация отжига – большая тема, и я точно не покрыл всё. Результаты могут сильно отличаться, если вы будуте решать коммивояжёра на большем наборе входных данных, или вообще другую задачу. Но я надеюсь, что вы получили некоторое представление о том, как это работает и как настраивать параметры.
Если вы не хотите читать статью полностью, вот короткий список советов:
- Всегда сохраняйте лучший встретившийся ответ, а не последний.
- Выводите количество проверенных переходов и сравнивайте это число с вашими ожиданиями.
- Выводите статистику того, как часто вы делаете плохие переходы.
- Сначала инициализируйте
temp_startиtemp_endочень маленьким и очень большим значениями, чтобы оценить ожидаемый результат. Затем двигайте их ближе друг к другу, пока всё не сломается. - Не оптимизируйте код сразу. Сначала увеличьте TL и проверьте, улучшается ли результат.
- Если вы действительно хотите оптимизировать, сделайте подсчёт скора за
O(1), кешируйте время и температуру и оптимизируйте генератор случайных чисел.
Код всех экспериментов доступен на GitHub.
Если вы дочитали до этого момента, рассмотрите возможность подписки на мой канал с похожими постами: https://t.me/bminaiev_blog.
Примечание по поводу перевода названия статьи: в оригинале обыгрывается многозначное слово converging, из-за чего название можно перевести и как “сходимость в имитации отжига”, и как “сосредотачиваемся на имитации отжига”.